The Change Nobody Will Notice—Until They Do
On June 2, at Build 2026 in San Francisco, Satya Nadella announced what most Copilot users will experience as a Tuesday morning with slightly different tab-complete behavior. Beginning in August, Project Polaris—Microsoft’s first in-house coding model—replaces GPT-4 Turbo as the default inference engine for every GitHub Copilot subscriber. Migration is automatic. There are no enrollment steps. GPT-4 Turbo remains available as an optional fallback through November, but after that window closes, Polaris is the engine.1
The developer sitting in VS Code will probably not notice the switch at all. Microsoft’s internal benchmarks show Polaris at parity with, or modestly ahead of, GPT-4 Turbo on mainstream languages like Python, TypeScript, and Java—the languages that make up the bulk of enterprise codebases.2 The transition is designed to be invisible.
But “invisible” is not the same as “without consequence.” For engineering leaders, architects, and the procurement and legal teams that audited Copilot before signing contracts, what changes in August is more than a model version. The dependency that enterprise risk teams documented as “OpenAI model via Microsoft”—a relationship with well-understood insurance, contractual protections, and liability pathways—is being replaced by a proprietary Microsoft model running on proprietary Microsoft silicon in proprietary Microsoft data centers. That is a different vendor-risk profile from the one enterprises agreed to, and it arrives without a re-procurement event.
It also arrives five weeks after Microsoft and OpenAI restructured the foundational partnership that made Copilot an OpenAI product in the first place.3
What Polaris Is, Technically
Understanding what changed requires a brief stop at architecture.
GPT-4 Turbo, like most large language models in general commercial deployment, is a dense transformer. Every parameter activates on every inference. You send a Go function, the model processes it through its full parameter set, and you get a completion back. Dense models are straightforward to reason about operationally: predictable latency, predictable token consumption, relatively simple capacity planning.
Polaris uses a Mixture-of-Experts architecture—MoE in the technical literature, now common among frontier models including DeepSeek-V3, Mixtral, and others in the open-source community.4 The fundamental idea is sparse activation: instead of a single model that applies all its parameters to every input, a routing mechanism—called a gating network—selects a small subset of specialized sub-networks (the “experts”) most relevant to the specific token or task at hand. DeepSeek-R1, to take a well-known example, carries 671 billion total parameters but activates only 37 billion per token.5
For Polaris specifically, Microsoft has built language-specific expert modules. A Rust query routes to a different sub-network than a Python query. Haskell and other low-resource languages—where generic dense models tend to hallucinate APIs and library calls that do not exist—are served by sub-networks trained specifically on those language corpora.6
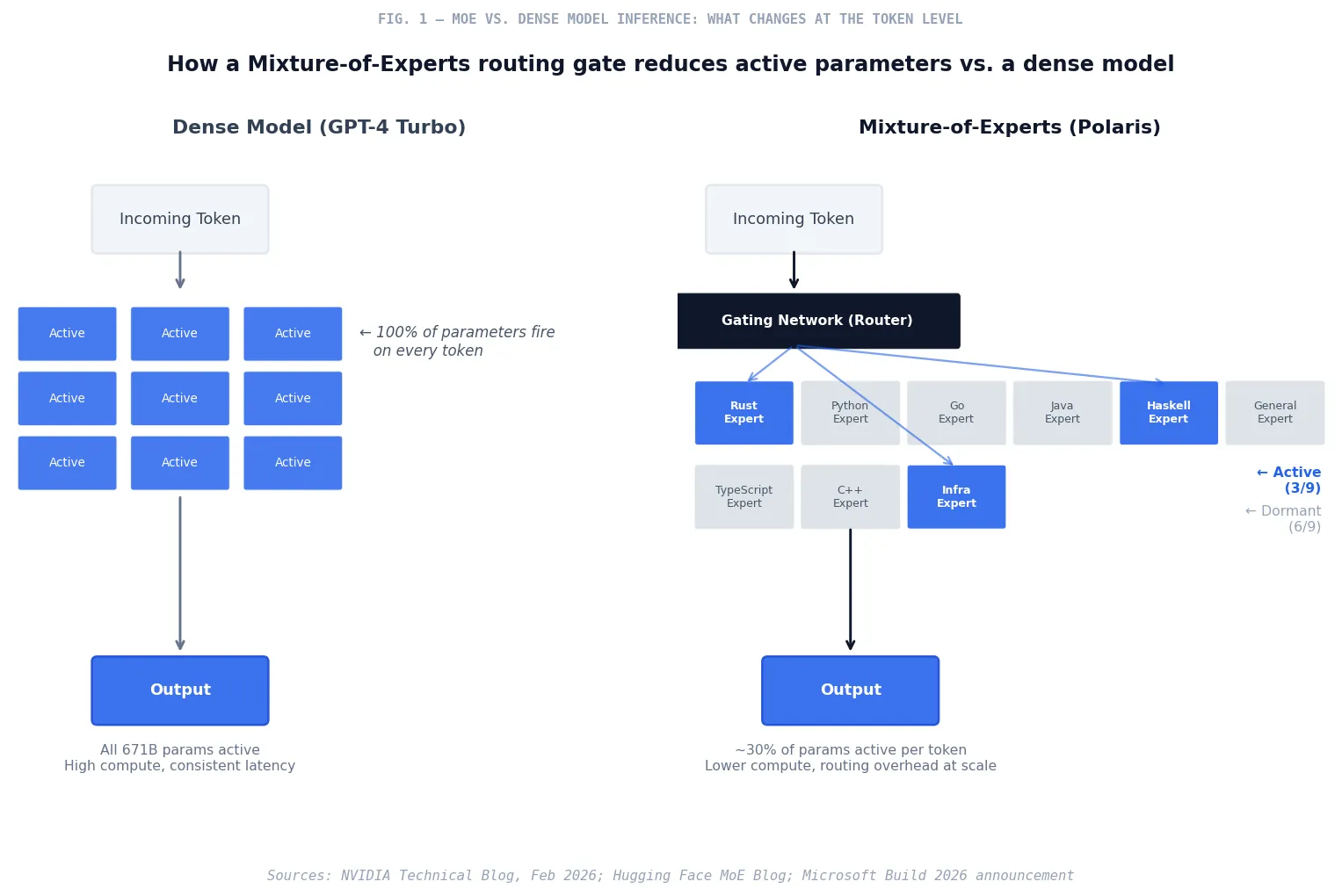
The practical implications for enterprise development teams are meaningful, though they require some nuance.
On performance: Microsoft claims Polaris outperforms GPT-4 Turbo on HumanEval and MBPP benchmarks, with the largest gains on low-resource languages.7 Those claims come from Microsoft, measured by Microsoft, on benchmarks chosen by Microsoft. As of publication, no independent auditor has verified the figures. Enterprise teams should treat them as a reasonable starting hypothesis, not a confirmed fact, and use the fallback window—which must be actively configured before August, not after—to test their actual workflows.
On latency: MoE models introduce routing overhead that dense models do not carry. A gating network must run, experts must be selected, and when those experts are distributed across multiple GPUs (as they are at Polaris’s scale), an all-to-all communication pattern must complete before outputs are aggregated. NVIDIA’s technical documentation on MoE deployment is explicit on this point: cross-device expert communication places significant strain on memory bandwidth, and high-performance networking is the primary mitigation.8 Maia’s custom inference architecture—216GB HBM3e at 7 TB/s bandwidth, scale-up interconnects across clusters of up to 6,144 accelerators—is designed precisely to absorb this overhead.9 Whether it does so at latencies acceptable to your development team is something to measure, not assume.
On cost: MoE architectures activate fewer parameters per token than dense models of equivalent capability, which reduces the per-token compute requirement. Combined with Microsoft’s ownership of the inference silicon—eliminating the external API margin that previously went to OpenAI—Polaris should represent meaningful per-token cost improvement for Microsoft. Whether that improvement flows to customers through pricing, or is captured as margin improvement, is a different question.
The Silicon Underneath
The part of this announcement that receives less coverage than the model is the hardware, and it may matter more in the long run.
Project Polaris runs on Maia 200, Microsoft’s custom inference accelerator, announced in January 2026.10 Fabricated on TSMC’s 3nm process with over 140 billion transistors, Maia 200 is purpose-built for AI inference—meaning its transistor budget is allocated entirely to the forward pass, not to training-era operations like backward propagation. Microsoft’s EVP of Cloud and AI, Scott Guthrie, said at launch that Maia 200 delivers 30% better performance per dollar than the prior generation of hardware in Microsoft’s fleet.11
The chip is deployed initially in US Central (Des Moines, Iowa) and US West 3 (Phoenix, Arizona).12 Global distribution is not yet complete. For enterprises with data residency requirements outside those regions, that is not a footnote—it is an operational constraint that procurement teams should confirm before August migration takes effect.
More structurally: what Microsoft has done with Polaris on Maia is what Amazon has done with Trainium for its models, and what Google has done with TPUs for Gemini. All three hyperscalers are executing the same vertical integration strategy—own the model, own the silicon, own the inference economics. The difference for Copilot users is that this shift happens automatically. No enterprise asked for a default switch to a new model class running on new hardware. It is simply arriving.
Stack Dependency When you subscribe to Copilot, you are not selecting a model—you are accepting whatever model Microsoft designates as default, running on whatever infrastructure Microsoft currently operates. Polaris is the first time that default moves from a third-party-supplied model to a Microsoft-proprietary one. It will not be the last.
IP Indemnification: The Enterprise Legal Question
For many enterprise procurement teams, the most consequential aspect of this transition is not architecture or silicon—it is liability.
GitHub’s Copilot Enterprise offering includes IP indemnification for unmodified suggestions when the content filtering settings are enabled. The specific requirement, per Microsoft’s documentation: compliance with the required mitigations for GitHub offerings, which includes maintaining Copilot’s duplicate detection filter.13 When those conditions are met, GitHub and Microsoft assume copyright responsibility for Copilot-generated code, not the customer.
This coverage now extends explicitly to Polaris-generated output under what Microsoft calls the Code Content Guarantee—trained on permissible data, with indemnification coverage from day one.14 For legal teams navigating ongoing copyright litigation around AI-generated code, the ability to transfer that liability to a vendor with the financial capacity of Microsoft is not a small thing. It is frequently the deciding factor in enterprise procurement conversations.
The catch—and it is a real one—is that indemnification coverage has conditions and limits that deserve careful legal review. Runtime.news published an analysis noting that the specific contract language in Copilot’s terms of service contains significant ambiguity around what “defense” means if generated code is combined with custom code and then incorporated into a larger product.15 The coverage is genuine. Whether it is comprehensive enough for your organization’s specific risk exposure requires counsel, not a vendor FAQ.
How does this compare to the broader market?
Anthropic extended copyright indemnification to Claude API and Enterprise customers in January 2024, covering both the defense of infringement claims and any approved settlements or judgments.16 GitHub’s Trust Center FAQ explicitly addresses whether third-party models available through Copilot—including Claude—are covered by Microsoft’s contractual indemnity commitments: they are not, by default. Third-party models available in Copilot’s model picker route through separate contractual arrangements with each provider.17
Cursor and Windsurf (now rebranded as Devin Desktop following its acquisition by Cognition) both offer SOC 2 Type II compliance and data privacy controls that prevent code from being used in model training—but neither offers the same first-party IP indemnification posture that Microsoft provides for Copilot-generated code on its own models.18 For regulated enterprises where legal review is a hard gate on tooling deployment, this distinction still matters, even as competitors narrow the compliance gap in other dimensions.
| Provider | IP Indemnification (Enterprise) | Training on Customer Code | Coverage Scope |
|---|---|---|---|
| GitHub Copilot (Polaris) | Yes — uncapped, first-party model output | No (Business/Enterprise) | Unmodified suggestions with filtering enabled |
| Anthropic Claude (Enterprise API) | Yes — defense + settlement coverage | No (Enterprise/API) | Authorized use of outputs |
| Cursor (Business/Enterprise) | No first-party indemnification | No (Privacy Mode / Business) | SOC 2 Type II; no IP coverage |
| Windsurf/Devin (Enterprise) | No first-party indemnification | No (Team/Enterprise) | FedRAMP/HIPAA; no IP coverage |
The Vertical Stack: What Changes at the Operational Layer
It is worth separating what the Polaris transition means at the model level from what it means at the platform level—because the platform implications may outlast the model-specific ones.
Before Polaris, GitHub Copilot’s inference chain looked like this: developer request → GitHub/VS Code → Microsoft Azure → OpenAI API → GPT-4 Turbo. Three entities controlled different pieces. Microsoft owned the distribution, identity, and developer tools layer. OpenAI owned the model. Azure provided the compute, with some overlap between the two.
After Polaris, the chain is: developer request → GitHub/VS Code → Microsoft Azure → Polaris on Maia. One entity controls everything from the silicon up. This is not hypothetical vertical integration—it is the same architectural consolidation that Google achieved with Gemini on TPUs and Amazon is pursuing with Bedrock and Trainium.

For developers who need only inline completion and basic chat, this change is genuinely irrelevant in practice. Polaris will serve those workflows well. The implications compound as you move up the autonomy stack.
Multi-agent mode—announced simultaneously at Build 2026 and now available in VS Code preview—changes the blast radius of these decisions.19 When an orchestrator agent spawns parallel sub-agents for linting, testing, documentation, and security review simultaneously, each of those sub-agents is making inference calls. The model routing each call is Polaris. The context for each call—potentially including proprietary source code, internal architecture patterns, API keys if not properly scoped—flows through Microsoft’s unified stack. The audit log for what was sent, when, and to which sub-component is only as detailed as what Microsoft exposes through its governance APIs.
Copilot Workspace, which reached general availability at Build 2026, extends this further: reasoning across entire repositories, proposing multi-file edits, running tests, and iterating autonomously on bounded tasks.20 Autonomous Agent Mode for Copilot Enterprise—full feature-branch commits with human approval required before merge—is on the July 2026 roadmap. Each tier of autonomy is a tier of expanded context exposure and deeper integration into the Microsoft operational stack.
The three-month fallback window deserves emphasis. It is not simply an escape valve for developers who find Polaris’s completion behavior different from GPT-4 Turbo’s. It is your organization’s only structured opportunity to run controlled evaluation of Polaris against your specific codebase, language mix, internal library patterns, and compliance requirements before the migration becomes permanent. That evaluation should have already started. If it has not, it needs to start now.
What the Partnership Restructure Tells You
Context matters here, and the context was set five weeks before Build 2026.
On April 27, Microsoft and OpenAI announced an amended partnership that ended the exclusive arrangement that had governed their relationship since 2019.21 OpenAI can now license its models to any cloud provider. AWS added OpenAI’s Codex—a direct Copilot competitor—to Bedrock essentially the next day.22 Microsoft retains access to OpenAI intellectual property through 2032, and the partnership continues, but the days of OpenAI models being default Microsoft product infrastructure are clearly numbered.
Polaris is not incidentally timed. Microsoft spent the last three years building a model development capability that would allow it to replace OpenAI as its Copilot default. MAI-Transcribe-1, MAI-Voice-1, and MAI-Image-2 were announced in April, replacing OpenAI models in other Microsoft products.23 Polaris is the coding piece of a deliberate, coordinated strategy to own the model layer of every major Microsoft product surface.
The strategic implication for enterprise customers is this: the organizations that signed Copilot contracts on the basis of an OpenAI model foundation should understand that foundation has changed. The model quality case for Polaris is plausible but unverified by independent parties. The vendor-risk profile is different in ways that deserve explicit re-examination—not because Polaris is worse, but because different is itself a change that enterprise governance frameworks are supposed to catch.
The Cost Equation, Honestly Evaluated
Gartner published a forecast in June 2026 that deserves direct attention: AI coding tool costs are projected to surpass the average developer salary by 2028 as token consumption from agentic workflows escalates.24 This is not a Polaris-specific problem—it is a category-wide trajectory driven by the shift from inline completion to agentic, multi-call workflows. But Polaris’s architecture intersects with it in specific ways.
MoE models, while compute-efficient per token, introduce routing overhead that can make batching behavior less predictable than dense models. Agentic workflows that issue many sequential or parallel model calls—exactly what Copilot Workspace and multi-agent mode enable—will consume tokens differently on Polaris than on GPT-4 Turbo. The per-seat pricing structure that most enterprise Copilot contracts are based on will not capture that variance cleanly. GitHub moved to a usage-based billing model in April 2026, exposing token-metered pricing alongside the flat seat tiers.25 That change is worth examining before August, not after you have discovered that your most active agent users burned through their monthly allocation in the first week.
Enterprise data from May 2026 puts total all-in AI tooling spend at $200 to $600 per engineer per month when usage-based overages are included—far above the headline seat license figures that most procurement models assume.26 Polaris does not change this dynamic, but the migration to a more capable model running deeper agentic workflows may accelerate it.
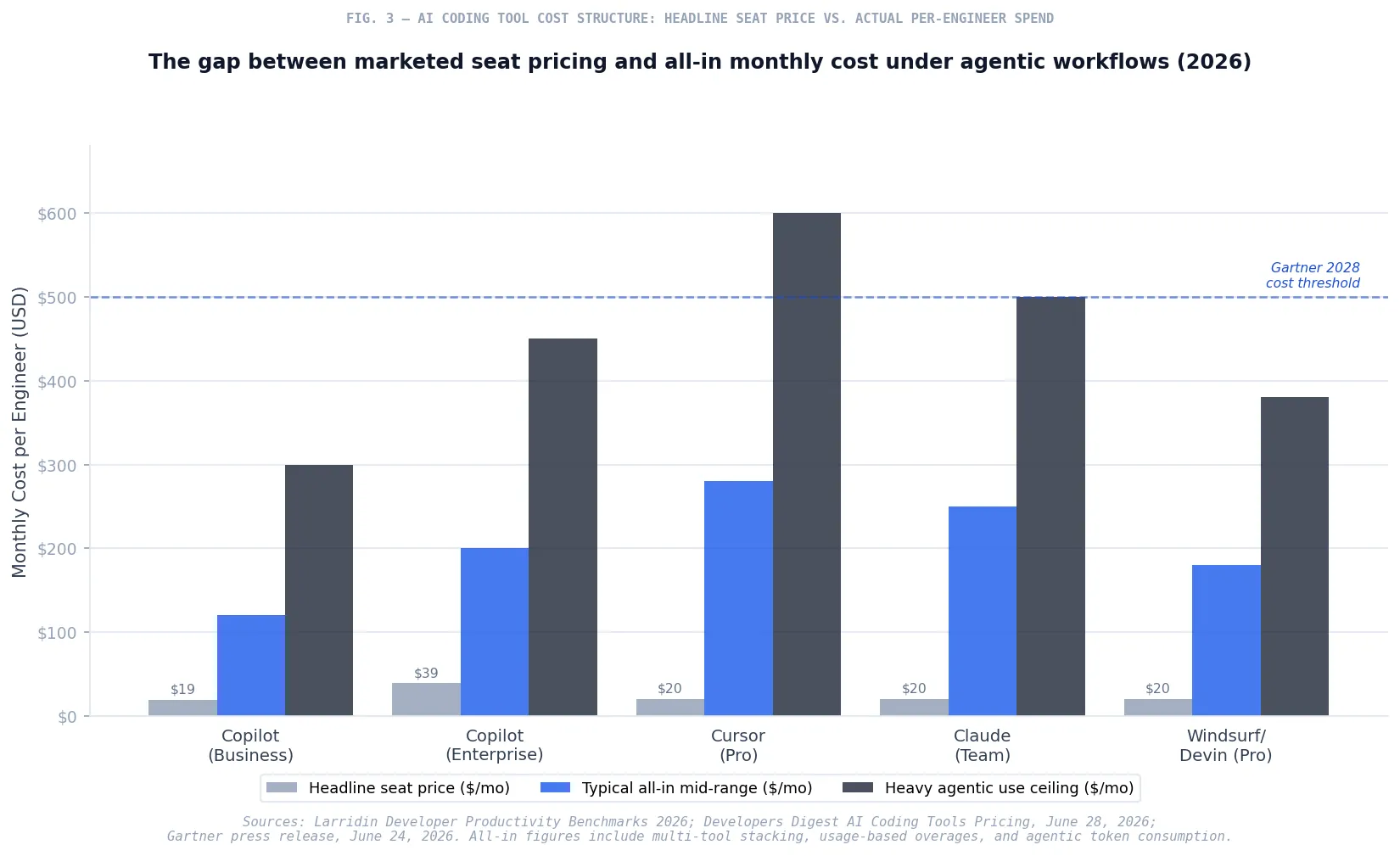
What Developers and Engineering Leaders Need to Consider
The framing here is not “stay with Copilot” or “leave Copilot.” The framing is “understand what you are buying as of August, not what you bought when you signed.”
Evaluate Polaris on your actual workloads before November. The fallback window is a structured testing opportunity. Use it. Do not rely on Microsoft’s benchmarks to predict behavior on your codebase, your internal libraries, or your niche languages. HumanEval and MBPP measure performance on well-defined code generation problems, not on the multi-file refactoring and domain-specific code completion that most production teams care about.
Re-examine your vendor-risk documentation. If your organization’s Copilot risk assessment documented an OpenAI dependency, that documentation is now stale. Update it to reflect a Microsoft-proprietary model on Microsoft-proprietary silicon. This is not necessarily an adverse change—many enterprises will read “Microsoft-on-Microsoft” as less risky than “Microsoft-on-OpenAI”—but it is a change, and it should be documented.
Scope agent access before expanding autonomy. Multi-agent mode and Copilot Workspace increase the volume and variety of code context routed to Microsoft’s inference infrastructure. Before enabling fleet or autopilot modes, verify that your data governance policies cover agentic context transmission at the same standard they cover chat and completion requests. They often do not.
Understand IP indemnification conditions specifically. GitHub’s coverage is real and has enterprise value. But coverage conditioned on maintaining duplicate detection filters and other required mitigations means that organizations that turn off those filters—for legitimate performance reasons, in some cases—may inadvertently void their indemnification. Confirm with counsel, not from the product documentation alone.
Account for MoE-specific cost unpredictability in agentic workflows. If your teams are moving into Copilot Workspace or multi-agent mode at scale, token consumption patterns on a MoE model will differ from what your budgets assumed under GPT-4 Turbo. Build measurement into your rollout before you discover the variance through an unexpected invoice.
The migration is automatic. The scrutiny that should accompany it is not.
The Architecture Owns the Answer
The Polaris announcement is being interpreted in several frames: a benchmark competition, a declaration of independence from OpenAI, a product capability expansion, a competitive move against Cursor and Claude Code. All of those readings are partially correct.
But for enterprise engineering and technical leadership, the most operationally useful frame is neither the model benchmarks nor the competitive positioning. It is the architecture question: what, exactly, flows through what, and who controls it?
Before August, Copilot’s inference chain had an external dependency—OpenAI—that created negotiating surface, separation of liability, and architectural redundancy. After August, that dependency disappears. Microsoft controls the model, the silicon, the inference infrastructure, and the developer experience. The routing layer that allows third-party models through the Copilot model picker is real, but it is an affordance built on top of a Microsoft-controlled substrate.
Whether that consolidation is a risk or an advantage depends on your organization’s relationship with Microsoft, your requirements for model portability, and your tolerance for a stack where a single vendor controls every layer. What it definitively is—regardless of where you land on those questions—is a structural change. The teams that recognize it as such, and update their governance and cost models accordingly, will be better positioned than the ones who notice it only when Polaris’s behavior surprises them on a production workflow in September.
References
- Let’s Data Science, “Microsoft Project Polaris Replaces GPT-4 in GitHub Copilot (Build 2026),” letsdatascience.com, June 2, 2026.
- AI Tool Briefing, “Microsoft Build 2026: Copilot Gets Its Own AI Model,” aitoolbriefing.com, June 2, 2026.
- Forbes, “OpenAI And Microsoft End Exclusive Partnership And Revenue Sharing,” forbes.com, April 27, 2026.
- NVIDIA, “Applying Mixture of Experts in LLM Architectures,” developer.nvidia.com, February 20, 2026.
- Build Fast With AI, “What Is Mixture of Experts (MoE)? How It Works (2026),” buildfastwithai.com, April 1, 2026.
- AIxploria, “Project Polaris: Microsoft Drops GPT-4 From GitHub Copilot and Goes In-House,” aixploria.com, June 2, 2026.
- TechTimes, “GitHub Copilot Replaces GPT-4 With Project Polaris, Ships Multi-Agent VS Code at Build,” techtimes.com, June 2, 2026. Note: Benchmark figures are Microsoft-sourced and have not been independently audited at time of publication.
- NVIDIA, “Mixture of Experts Powers the Most Intelligent Frontier AI Models,” blogs.nvidia.com, March 3, 2026.
- Microsoft, “Maia 200: The AI Accelerator Built for Inference,” blogs.microsoft.com, January 26, 2026.
- Ibid.
- Forbes, “Microsoft Unveils A New AI Inference Accelerator Chip, Maia 200,” forbes.com, January 26, 2026. Quoting Mustafa Suleiman, CEO of Microsoft AI.
- Microsoft Source EMEA, “Microsoft Introduces Maia 200: New Inference Accelerator Enhances AI Performance in Azure,” news.microsoft.com, January 26, 2026.
- GitHub Trust Center, “What Are the Requirements to Secure IP Indemnification When Using GitHub Copilot Business or Copilot Enterprise?” copilot.github.trust.page, accessed July 2026.
- ByteIota, “GitHub Copilot Gets Its Own AI Model: Project Polaris,” byteiota.com, May 31, 2026.
- Runtime.news, “AI Vendors Promised Indemnification Against Lawsuits. The Details Are Messy,” runtime.news, January 2, 2024.
- Anthropic, “Expanded Legal Protections and Improvements to Our API,” anthropic.com, December 19, 2023.
- GitHub Trust Center, “Are Third-Party Models Covered by GitHub and Microsoft’s Contractual Indemnity Commitments?” copilot.github.trust.page, accessed July 2026.
- Value Add VC, “Best AI Coding Tools 2026 Ranked,” valueaddvc.com, June 2026.
- Vibe Coder Blog, “GitHub Copilot Ships Project Polaris and Multi-Agent VS Code,” blog.vibecoder.me, June 2, 2026.
- ChatForest, “Microsoft Build 2026 Recap: Windows Is Now an Agent Platform,” chatforest.com, June 2, 2026.
- Redmond Magazine, “Microsoft, OpenAI Restructure Partnership in Shift Away from Exclusivity,” redmondmag.com, April 28, 2026.
- CNBC, “OpenAI’s Subtle Drift from Microsoft Has Become an Aggressive Move Toward Amazon,” cnbc.com, April 29, 2026.
- AI Weekly, “Microsoft Drops GPT-4 Turbo for Polaris in GitHub Copilot,” aiweekly.co, June 2, 2026.
- Gartner, “Gartner Predicts AI Coding Costs Will Surpass Average Developer’s Salary by 2028 as Token Consumption Surges,” press release, gartner.com, June 24, 2026.
- AI Business Weekly, “Microsoft Copilot Statistics 2026: Users, Seats & Market Share,” aibusinessweekly.net, June 2026.
- Larridin, “Developer Productivity Benchmarks 2026,” larridin.com, March 20, 2026.