The Bill Arrives
In April 2026, Uber’s CTO, Praveen Neppalli Naga, confirmed publicly what many enterprise technology leaders had been discovering in quarterly reviews: the company had burned through its entire 2026 AI coding-tools budget in four months.1 The driver was not a runaway experiment. It was adoption working as designed. Uber had incentivized its 5,000-person engineering organization to use AI tools as aggressively as possible, ranking teams by consumption on internal leaderboards. Claude Code adoption jumped from 32 percent to 84 percent of the workforce. Per-engineer monthly costs ran between $500 and $2,000.2 The budget, set in fall 2025 before the current generation of coding agents existed in their present form, was structurally incompatible with the world it was supposed to govern.
Uber subsequently implemented a per-tool monthly cap of $1,500 per employee on agentic coding software.3 That response—a ceiling imposed after the fact—is the most common enterprise AI governance pattern of 2026. It is reactive by definition and should not be the template.
The Uber episode is illustrative, not exceptional. A separate enterprise consumed 1 trillion tokens over six months, resulting in more than $6 million in unplanned costs before the finance team understood the mechanism generating them.4 One organization spent half a billion dollars in a single month after failing to set usage limits on its AI licenses.5 These are the predictable output of deploying consumption-based infrastructure without the financial discipline it requires.
This article addresses the underlying economics: why usage-based billing for AI was structurally inevitable, what token economics mean at the enterprise level, and how CFOs and CTOs can build the governance framework that transforms a variable cost into a managed line item.
The Core Tension Per-token prices have fallen 67 percent year over year, from $18.40 to $6.07 per million tokens between Q1 2025 and Q1 2026. Total enterprise AI spend is rising sharply. The math is not contradictory. Volume is growing faster than unit costs are falling—and that gap will widen as agentic workloads scale.
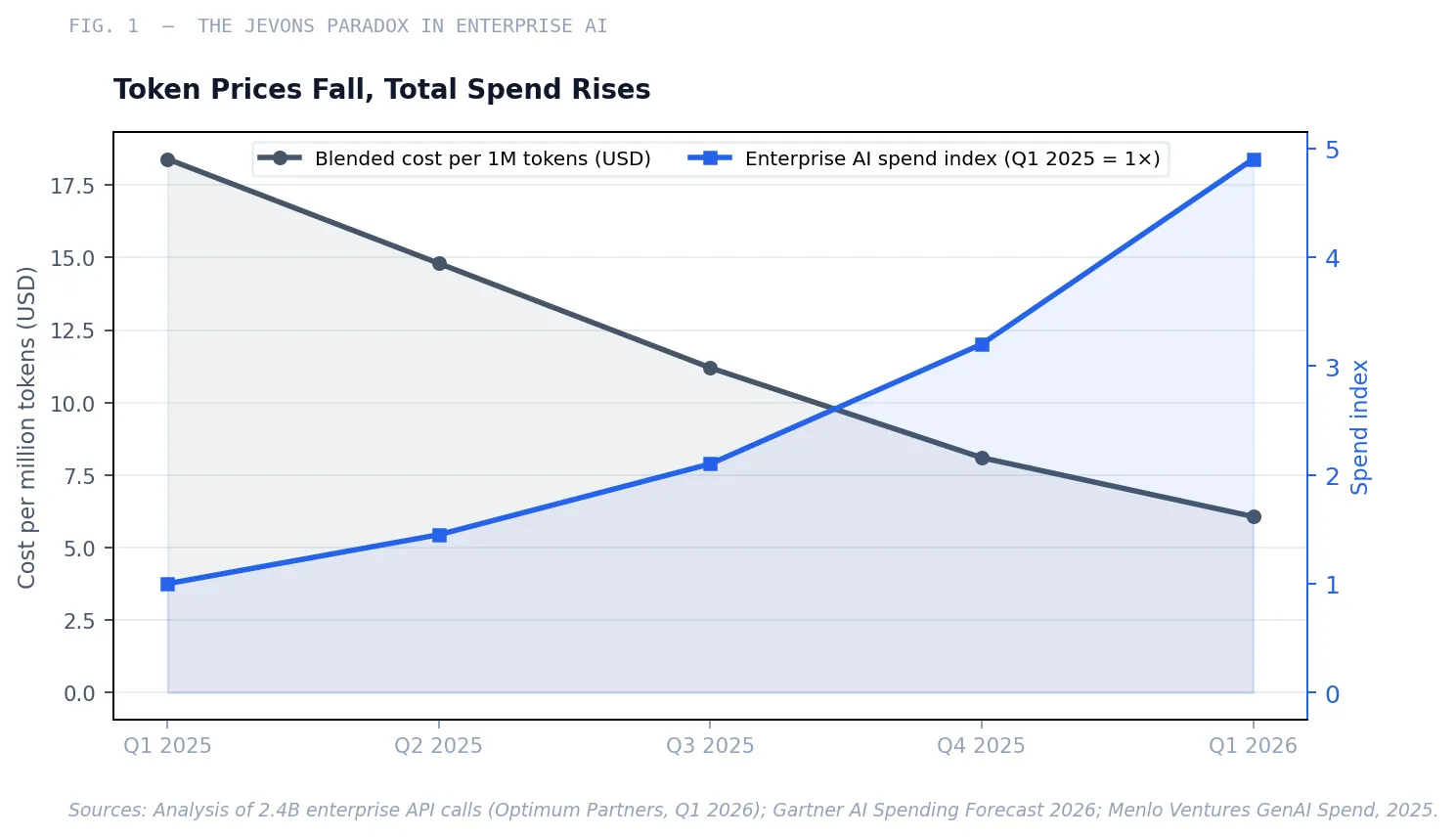
Why the Flat-Rate Era Ended
When AI tools entered the enterprise as assistants—chat interfaces, code completion, summarization—their usage pattern was narrow enough that subscription economics made reasonable sense. Interactions were short, stateless, and bounded. A developer typed a prompt, received a suggestion, accepted or rejected it, and moved on. The variance in per-user consumption was low enough that a vendor could set a seat price, absorb the spread, and sustain a business.
That model ended with agentic AI. An agent does not respond to a prompt—it executes a chain of operations: reading context, calling tools, retrieving documents, reasoning over results, generating outputs, verifying them, and iterating. Each step consumes tokens. Agentic workflows consume 10 to 50 times the tokens of a single conversational turn.6 A coding agent reading across a large repository, running tests, and proposing a multi-file refactor can consume in an hour what a traditional assistant consumed in a week.
This creates an economic impossibility for flat-rate pricing. When a vendor offers unlimited access to a tool that can generate hundreds of dollars of compute in a single session, the subscription price becomes a subsidy—and subsidies require a funder. In 2023 and 2024, that funder was venture capital. By 2025, with compute costs rising and adoption scaling, the model reached its structural limit.
The convergence visible in the market now is that the subsidy era ended across every major AI platform simultaneously—not because vendors chose to act in concert, but because the economics arrived at the same conclusion at the same time.
“As enterprises move generative and agentic AI workloads from pilot to production, tokens have become the new unit of technology spend.”
— Jim Zemlin, CEO, Linux Foundation, announcing the Tokenomics Foundation, June 3, 2026
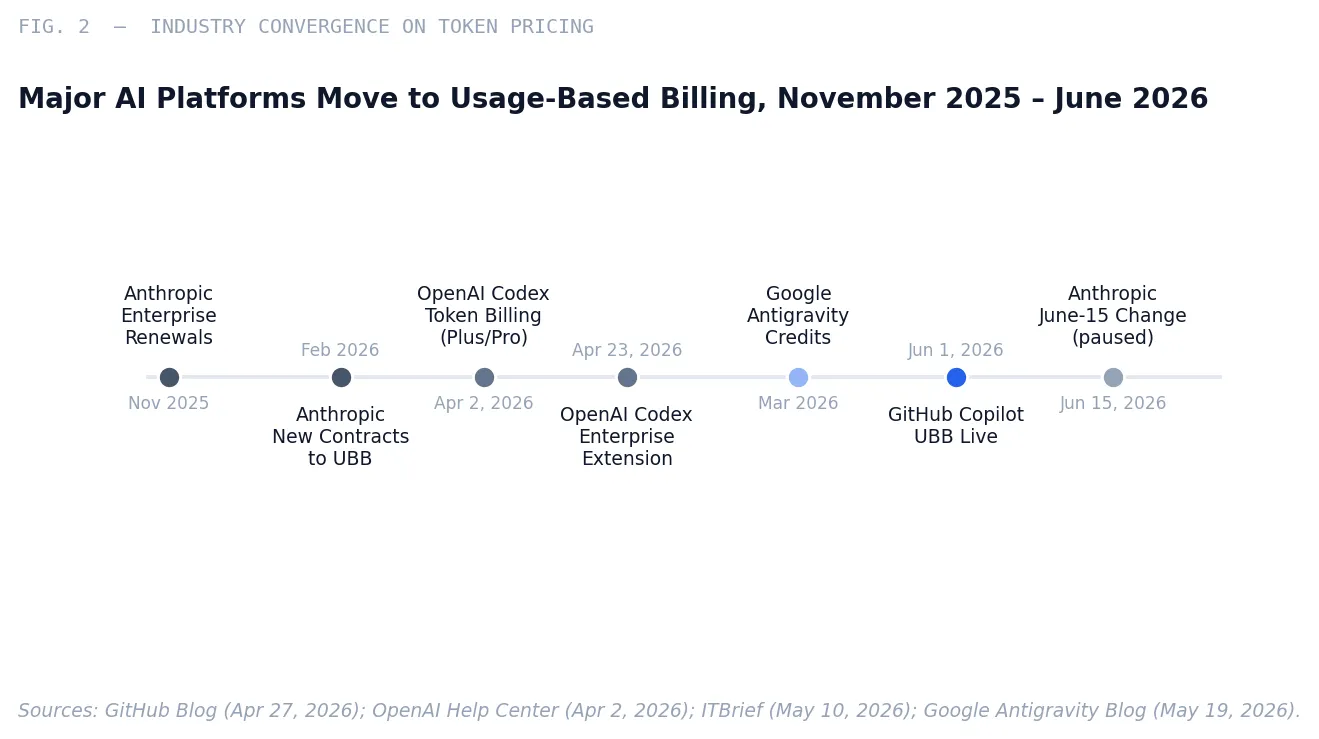
GitHub Copilot moved all plans to usage-based billing effective June 1, 2026, replacing premium request units with a credit system tied directly to token consumption.7 OpenAI shifted Codex from per-message pricing to token-based credit billing across Plus, Pro, and Enterprise plans on April 2, 2026.8 Anthropic revised its enterprise billing structure beginning in November 2025, moving renewing accounts from bundled-token seat plans to a base platform fee plus metered API usage at standard rates, effective for new contracts from February 2026 and all renewals from March 2026.9 Google’s Antigravity introduced a credit system in March 2026, converting from fixed quota tiers to token-linked consumption, and restructured its paid tiers at I/O 2026 with unified rate limits drawn down as per API pricing.10
The simultaneity of these moves is not coincidence. It reflects a shared underlying reality: Blackwell GPU rental prices increased 48 percent between February and April 2026.11 Bank of America projects compute demand will exceed supply through 2029.12 The compute required to run frontier agentic models at enterprise scale cannot be financed by subscription revenue priced for a much simpler workload. Something had to give—and what gave was the fiction that AI tooling could be sold like SaaS.
The Pricing Shift in Brief Token-based pricing is not a strategy vendors adopted to extract more revenue. It is the structural outcome of agentic workloads consuming an order of magnitude more compute than conversational workloads—charged at rates that now reflect actual infrastructure cost rather than VC subsidy.
The Mechanics of Token Spend
A token is the fundamental unit of computation for a large language model. An LLM does not process words or sentences; it processes tokens, which are roughly equivalent to four characters of English text. Every piece of text sent to a model—the system prompt, the user query, any retrieved context, file contents, tool outputs—is tokenized and counted as input. Everything the model generates in response is tokenized and counted as output. Output tokens are consistently more expensive than input tokens across every major provider, because generation requires more compute than reading.
Understanding this structure matters for financial leaders because cost behavior differs dramatically by use case.
| Workflow Type | Approx. Token Consumption | Cost Behavior | Example |
|---|---|---|---|
| Single conversational turn | 500–2,000 tokens | Predictable; low variance | Asking an assistant to summarize a paragraph |
| Document processing | 5,000–50,000 tokens | Moderate; scales with document length | Reviewing a contract or research report |
| RAG-enabled query | 10,000–100,000 tokens | Variable; depends on retrieval scope | Enterprise knowledge base search with grounding |
| Agentic coding session | 100,000–2,000,000 tokens | Highly variable; compounds with repo size and session length | Multi-file refactor across a large codebase |
| Background monitoring agent | Continuous; per-event | Structurally unbounded; runs without user initiation | Compliance surveillance, document watching, pipeline monitoring |
The last two rows are where enterprise budget models break. Agentic coding sessions are the most visible because they involve a named user generating a specific output. Background agents are more dangerous precisely because they are invisible: they run continuously, consume tokens against every event and data update they process, and generate no single large invoice line that would trigger a review. These workloads were minimal in most 2024 enterprise deployments. In 2026, they represent a rising and structurally unbounded share of the monthly inference bill.
The Jevons paradox applies directly here. As the cost per token falls, engineers find more uses for tokens. Workflows that were impractical at $15 per million output tokens become routine at $5. Total consumption rises faster than unit prices fall, which is why the FinOps Foundation’s 2026 State of FinOps report found that 73 percent of enterprises reported AI costs exceeding original projections even as per-token prices declined across the industry.13
One additional dynamic compounds the problem at scale: model selection. The spread between the cheapest and most expensive frontier model output tokens is greater than 375-fold across the market.14 Routing every task to a frontier model when a lightweight model would produce a sufficient result is one of the single most expensive decisions an enterprise can make—and most enterprises are making it by default, because the routing decision is invisible without governance.
What This Means for CFOs and CTOs
The enterprise AI budget problem is not primarily a technology problem. It is a financial operations problem—the application of consumption-cost governance disciplines to a new and fast-moving expenditure category. The discipline exists: Cloud FinOps developed a mature methodology for governing variable compute spend over the last decade. Token economics requires the same framework applied to a category that moves faster and with higher variance.
Several dimensions distinguish token spend from traditional software licensing:
Cost is nonlinear by user. A 500-seat AI deployment does not generate 500 equivalent monthly bills. One engineer running heavy agentic sessions may consume 100 times the tokens of a colleague using the tool for occasional queries. Budgeting on a flat per-seat average produces systematic underestimates for high-adoption cohorts.
Cost is nonlinear by use case. Shifting an engineer from conversational assistance to agentic workflows can multiply monthly token spend by an order of magnitude without any change in seat count.
Cost compounds in agentic loops. A coding agent that reads a file, writes code, runs tests, reads the output, and iterates may process the same underlying content three to five times across a session. Most cost-per-session estimates engineers provide to finance teams undercount this reprocessing.
Cost is invisible without instrumentation. Token usage does not surface automatically in standard IT asset management tooling. Without purpose-built usage dashboards, finance teams have no visibility until the invoice arrives.
The CFO’s Risk Surface Token spend is variable, nonlinear, invisible without instrumentation, and structurally correlated with the most productive behaviors in your engineering organization. Managing it through hard cutoffs suppresses productivity. Managing it without governance produces Uber’s outcome. The answer is tiered budgets with real-time visibility.
Only 15 percent of enterprises can forecast AI costs within plus-or-minus 10 percent accuracy. Nearly one in four miss their AI cost forecast by more than 50 percent.15 These are not planning failures in the traditional sense—they reflect applying a linear seat-cost model to a nonlinear consumption phenomenon.
A Governance Framework for Token Economics
The enterprise governance problem has a tractable solution. It requires five components: classification, budgeting, hierarchy, instrumentation, and optimization. None is technically complex. All require deliberate implementation.
1. Classify Your Workloads Before You Price Them
Before setting any budget, classify your AI workloads by consumption profile. A financial summary assistant looks nothing like a coding agent rebuilding a microservice. Treating them identically guarantees the wrong answer for both.
A workload classification should capture at minimum: the category of use (conversational, document processing, retrieval-augmented, agentic, background), the expected token volume per session, the model tier required, and the business function it serves. This exercise also surfaces the highest-return optimization available without any workflow change: identifying where a frontier model is serving tasks a lightweight model would handle adequately.
2. Set Tiered Budgets by User Role, Not by Head Count
The most effective budgeting structure matches token allocation to the actual consumption profile of each role category. A budget designed around role archetypes rather than flat per-seat averages produces better cost control and better resource allocation simultaneously.
The following table is illustrative. Actual figures will vary by organization, tooling stack, and model choice—and should be derived from a 30-day usage audit before final budget setting.
| Role Archetype | Typical Use Pattern | Suggested Monthly Budget Range | Notes |
|---|---|---|---|
| Business user (BDM, analyst, operations) | Document review, summarization, Q&A, drafting | $20–$60/month | Predictable; lightweight models sufficient for most tasks |
| Power knowledge worker (lawyer, consultant, researcher) | Deep document analysis, long-context synthesis, structured reasoning | $75–$200/month | Higher context requirements; occasional frontier model use justified |
| Software engineer (non-agentic primary use) | Code completion, conversational coding assistance, code review | $100–$300/month | Moderate variance; heavy review workflows drive upper end |
| Software engineer (agentic primary use) | Autonomous multi-file tasks, CI/CD integration, parallel agents | $300–$1,500/month | High variance; requires real-time monitoring; justify with output metrics |
| AI/ML engineer or data scientist | Model evaluation, pipeline automation, large-context data processing | $500–$2,000/month | Highest consumption tier; batch processing and caching essential |
Two operational notes: First, the upper end of the agentic engineer range reflects published per-engineer spend ranges reported by Uber and corroborated by vendor documentation—it can be justified by output when properly measured. Second, the business user range is deliberately conservative; many deployments overspend here by defaulting to frontier models for tasks a sub-$1-per-million-token model handles adequately.
3. Implement a Budget Hierarchy
Individual role budgets do not operate in isolation. Effective token governance requires a layered structure with controls at multiple levels, each serving a distinct function.
Vendor platforms increasingly provide native controls for this. GitHub Copilot’s enterprise billing supports budget controls at the enterprise, organization, cost-center, and individual-user level simultaneously, with the ability to block or permit additional usage at metered rates when allocations run out.16 Microsoft’s Copilot Credit system for Copilot Cowork operates similarly.17
At the enterprise level: set a hard annual cap with a monthly allocation and a reserve. This is the ceiling from which everything derives. At the cost-center level: allocate from the enterprise pool by planned workload intensity—engineering departments running agentic workflows warrant higher allocations than teams using primarily document-processing use cases. At the team level: enable allocation tracking by project, connecting token spend to discrete deliverables and output value. At the individual level: set soft caps with monitoring and hard caps where unlimited agentic consumption is not justified by role scope. Soft caps generate alerts; hard caps enforce spending stops.
The Governance Principle Hard caps protect the budget floor. Soft caps protect the relationship with engineers. The most effective governance systems combine hard enterprise-level ceilings with graduated warnings at individual levels—so engineers see cost pressure building before they hit a wall.
4. Instrument Before You Deploy
The AI governance failures of 2025 and 2026 share a common structural feature: deployment preceded instrumentation. Teams shipped agentic tools before they had any mechanism for real-time cost visibility. The invoice was the first signal.
Reverse that sequence. Before any agentic deployment at scale, put in place: a real-time token usage dashboard breaking down consumption by user, team, project, and model; alert thresholds at 50, 75, and 90 percent of monthly allocation with escalating notification paths; API-based reporting integration with the finance system; and a model-selection audit log.
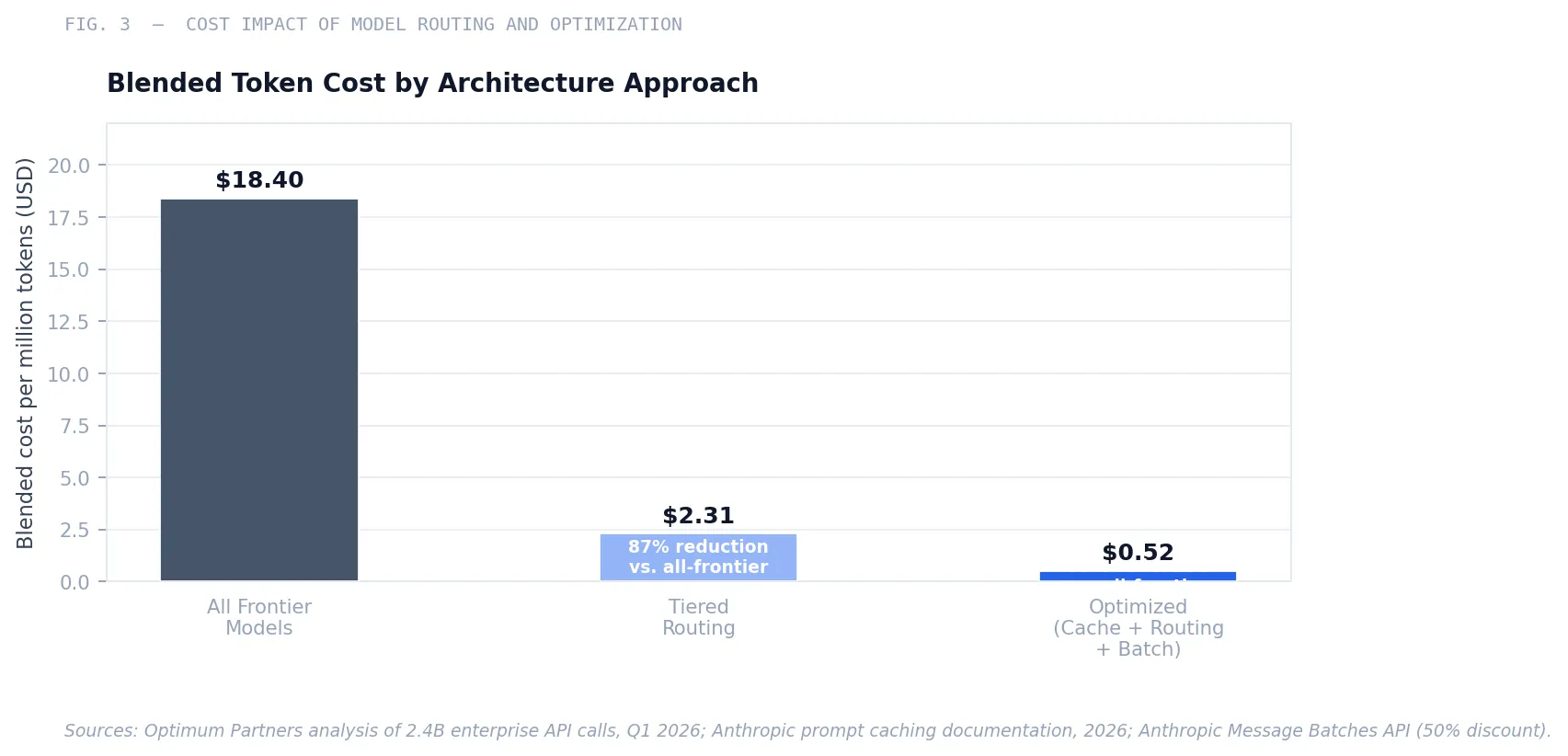
The last item deserves particular attention. Model selection is invisible in most deployments—users default to whatever the tool selects, which is typically a frontier model. An analysis of 2.4 billion enterprise API calls found that organizations running tiered model architecture paid a median blended cost of $2.31 per million tokens, versus $18.40 for organizations routing everything to frontier models—an 8× cost differential for identical volume.18
5. Optimize Systematically with Three Levers
Once instrumentation is in place and the budget hierarchy is set, three technical interventions deliver the most significant cost reduction:
Prompt caching. When a model has already processed large, stable context—a lengthy system prompt, a codebase unchanged between sessions, a document corpus used across multiple queries—that processed context can be cached and reused. Cached input tokens cost approximately 10 percent of standard input token rates.19 For agentic workflows that reload the same codebase repeatedly, this is not a marginal saving—it is a 90 percent cost reduction on the cached portion.
Model routing. Match the model to the task. A taxonomy of tasks by required tier—lightweight ($0.10–$1.00 per million tokens), capable general-purpose ($3–$15), and frontier reasoning ($15–$50+)—enables systematic routing that preserves quality where it matters and eliminates cost where it does not. Simple classification, formatting, FAQ responses, and standard summaries rarely require frontier capability.
Batch processing. Async batch APIs offer 50 percent cost reductions in exchange for non-real-time processing.20 Document review queues, bulk data processing, and compliance auditing are natural candidates—any use case where response latency is not a user experience constraint.
These three levers, applied together on a well-instrumented deployment, can reduce effective blended token costs by 60 to 80 percent relative to unoptimized frontier-model deployments.
The Counterargument: Why Cost Controls May Cost More Than They Save
It would be intellectually incomplete to present token governance purely as cost control. Uber’s COO acknowledged that the company could not draw a clear connection between its AI spend and measurable consumer-facing value improvements.21 That observation is fair. But the policy response—a $1,500 monthly cap per tool per engineer—is a blunt instrument. It reduces consumption without directing the reduction toward low-value usage.
The effective risk is misidentified. The risk is not that enterprises spend too much on AI. The risk is that governance frameworks designed to reduce cost will suppress high-value agentic workflows while having proportionally little impact on low-value conversational usage that generates volume but not economic return.
A hard cap, applied uniformly, is indifferent to the difference between an engineer spending $800 to complete a $200,000 refactor and a different engineer spending $800 on unstructured exploration that produces nothing deployable. Both hit the ceiling. Only one should.
Effective governance connects token consumption to business output—by project, by team, by deliverable. Gartner’s finding that fewer than 1 percent of executives report ROI of 20 percent or greater from AI investments22 is not an indictment of AI—it is an indictment of the measurement frameworks around it. Tokens are the input. Features shipped, contracts reviewed, decisions made faster are the output. Until governance connects those two measurements, the budget conversation will remain structurally imprecise—and imprecision serves neither the enterprise nor its vendors.
The Action Framework
Financial and technology leaders with AI tooling already deployed should act in priority order:
Audit first. Before any governance structure is meaningful, the enterprise needs a 30-day baseline of actual token consumption by user, role, team, and model. Most enterprises have never done this. The audit is the prerequisite for everything else.
Classify workloads. Map current AI use cases to the consumption profiles described above. Identify which workloads are generating background inference that is not user-initiated and which are using frontier models for tasks that do not require frontier capability.
Build the hierarchy before expanding the deployment. The most common pattern in 2026 is deploy broadly, govern later. Reverse it. Set enterprise-level allocations and individual-level alerts before expanding seat counts or enabling agentic features broadly. The governance infrastructure takes days to implement; cost recovery after a blowout takes quarters.
Implement the three technical levers. Prompt caching, model routing, and batch processing are available now on every major platform. They require engineering time to configure but no additional vendor spend. The ROI is reduction of the token bill, not future feature development.
Measure outputs, not inputs. Build the framework that connects AI spend to business outcomes—lines of code shipped, contract review throughput, customer resolution rates—before the next budget cycle. Without it, the CFO cannot justify the spend and the CTO cannot defend the tooling.
Renegotiate contracts with governance data. Enterprises approaching renewal with detailed consumption analytics and a commitment-use profile are in a materially different position than those renewing on seat count. Volume commitments, batch commitments, and prepaid capacity can reduce effective token costs by 20 to 40 percent for enterprises with predictable baseline workloads.
The Closing Argument
The token is not a pricing gimmick. It is the fundamental unit of economic value exchange in AI. A token represents a quantum of intelligence applied to a specific problem—the compute required to read context, reason over it, and generate a useful output. Every seat-based subscription that existed in the AI market was always implicitly charging for tokens; the abstraction simply hid the meter.
What changed in 2026 is that the meter became visible. That visibility is, on net, good for enterprise buyers—even if the short-term experience is disruptive. It creates the conditions for rational procurement, workload optimization, and outcome measurement that were impossible under flat-rate subscription models. The enterprise that treats the arrival of token economics as a crisis is the enterprise that was benefiting from opacity and now must build discipline. The enterprise that treats it as the forcing function for a governance framework it should have had two years ago will be better positioned for the next generation of AI deployment than any of its peers who are still managing the budget conversation as a cost-containment exercise.
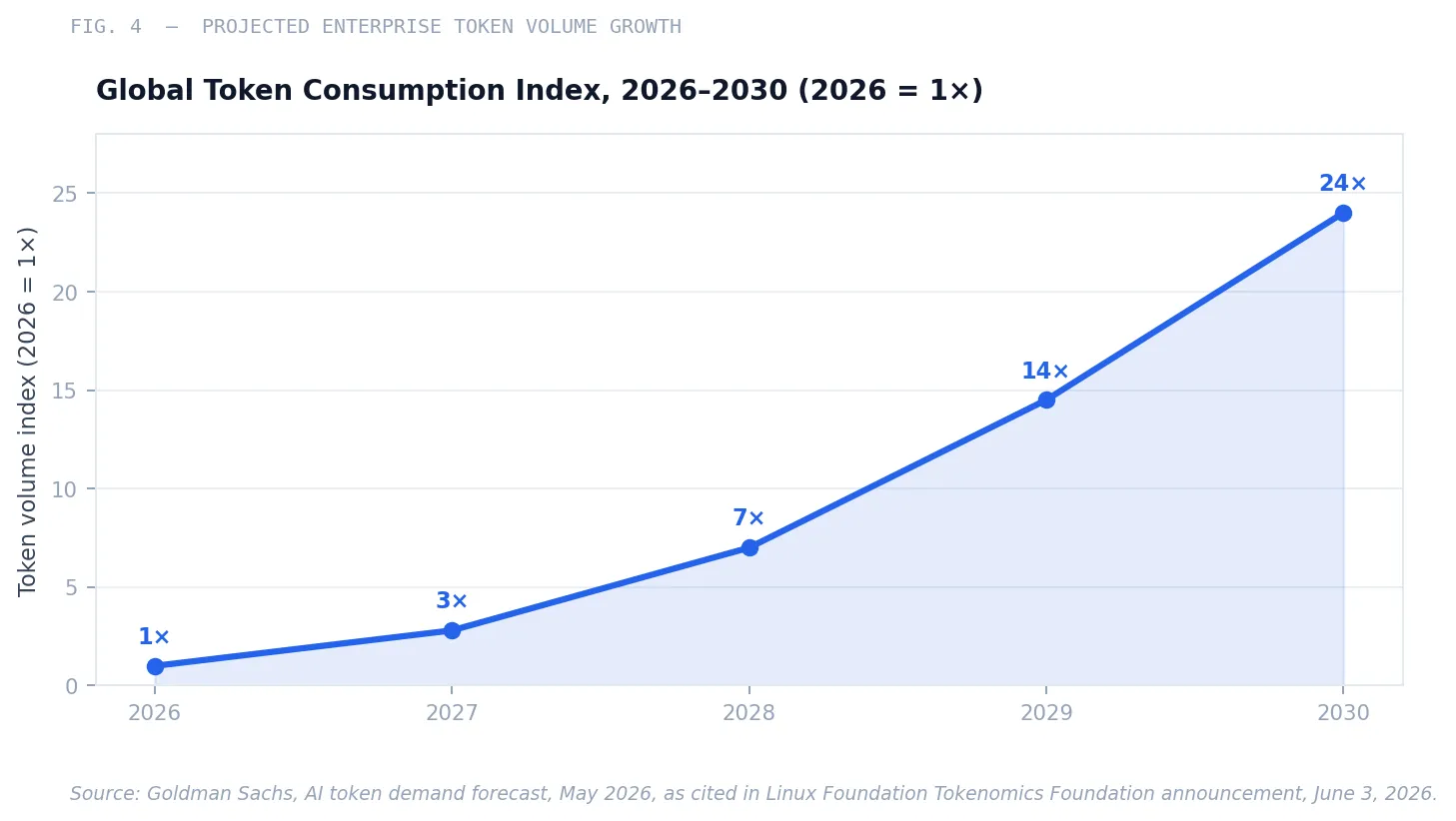
Goldman Sachs projects global token consumption will reach 120 quadrillion tokens per month by 2030—24 times the current level—driven primarily by enterprise agentic workloads.23 The enterprise that builds the financial governance infrastructure to manage token economics now is not merely solving a 2026 budget problem. It is building the operating model for the primary variable cost of enterprise technology for the next decade.
References
- Fortune, “Uber burned through its entire 2026 AI budget in four months. Now its COO is questioning whether it’s worth it,” May 26, 2026.
- AI Weekly, “Uber Exhausts AI Budget as Claude Code Hits 84%,” April 2026.
- TechCrunch, “Uber caps employee AI spending after blowing through budget in 4 months,” June 2, 2026; Bloomberg, reported same date.
- Elvex, “AI Token Cost Enterprise: Stop Budget Blowouts in 2026,” May 21, 2026.
- Paul Roetzer, SmarterX, The Artificial Intelligence Show, Episode 217, May 2026; reported by SmarterX AI.
- Gartner, as cited in ADVISORI, “AI Costs 2026: Why They’re Exploding & How to Cut Them,” June 2026 (agentic workloads consume 5–30× compute of standard interactions).
- Mario Rodriguez, GitHub Blog, “GitHub Copilot is moving to usage-based billing,” April 27, 2026.
- OpenAI Help Center, “Codex rate card,” updated April 2, 2026.
- ITBrief, “Anthropic shifts enterprise billing to token-based pricing,” May 10, 2026; The Register, “Anthropic ejects bundled tokens from enterprise seat deal,” April 16, 2026.
- Google Antigravity Blog, “Changes to Antigravity Plans,” May 19, 2026; TechCrunch, “Google launches Antigravity 2.0,” May 19, 2026.
- Ornn Compute Price Index, April 13, 2026, as reported by Tech-Insider, “Nvidia Blackwell GPU Rental Hits $4.08/hr: 48% Surge,” April 13, 2026.
- Bank of America semiconductor team forecast, as cited in ITBrief, May 2026.
- FinOps Foundation, State of FinOps 2026, as cited in Optimum Partners, “AI Token Costs: Why Enterprise AI Bills Keep Rising in 2026,” May 2026.
- The AI Enterprise, “The New Enterprise Currency: Why Your AI Strategy Lives or Dies by the Token,” March 13, 2026.
- Mavvrik / BenchmarkIT, State of AI Cost Governance, as cited in Mavvrik AI, “AI Cost Statistics 2026,” May 5, 2026.
- GitHub Copilot Adoption Resources, “Managing Copilot usage-based billing,” 2026.
- SoftwareOne blog, “Copilot Cowork launch: what it means for you,” June 16, 2026.
- Optimum Partners, “AI Token Costs: Why Enterprise AI Bills Keep Rising in 2026,” analysis of 2.4 billion enterprise API calls, May 2026.
- Kingy AI, “Usage-Based Billing, No Flat Rate: Why Anthropic’s 2026 Pricing Shift Changes Everything,” April 15, 2026.
- ECorpIT, “Microsoft & Uber Claude Code Costs in 2026,” May 28, 2026.
- Fortune, “Uber burned through its entire 2026 AI budget in four months,” May 26, 2026.
- Mavvrik AI, “AI Cost Statistics 2026,” citing Forbes Research, May 5, 2026.
- Goldman Sachs, as cited in Linux Foundation press release, “Linux Foundation Announces the Intent to Launch the Tokenomics Foundation,” June 3, 2026; BigGo Finance, “Goldman Sachs Predicts Token Demand to Surge 24x by 2030,” May 9, 2026.