The scatter diagram, or scatter plot, is a type of mathematical diagram of XY coordinates used to display values for a set of data. Typically, one value is under control while the other varies based on our control. For a quality assurance example, our control may be the number of features, while the variable is the number of bugs. The data for a scatter diagram is based over time or experience. In the graph below, I’ve generated some sample data for features and resulting bugs. The X axis is the number of features introduced in a given sprint while the Y axis is the number of bugs introduced by those features, respectively. 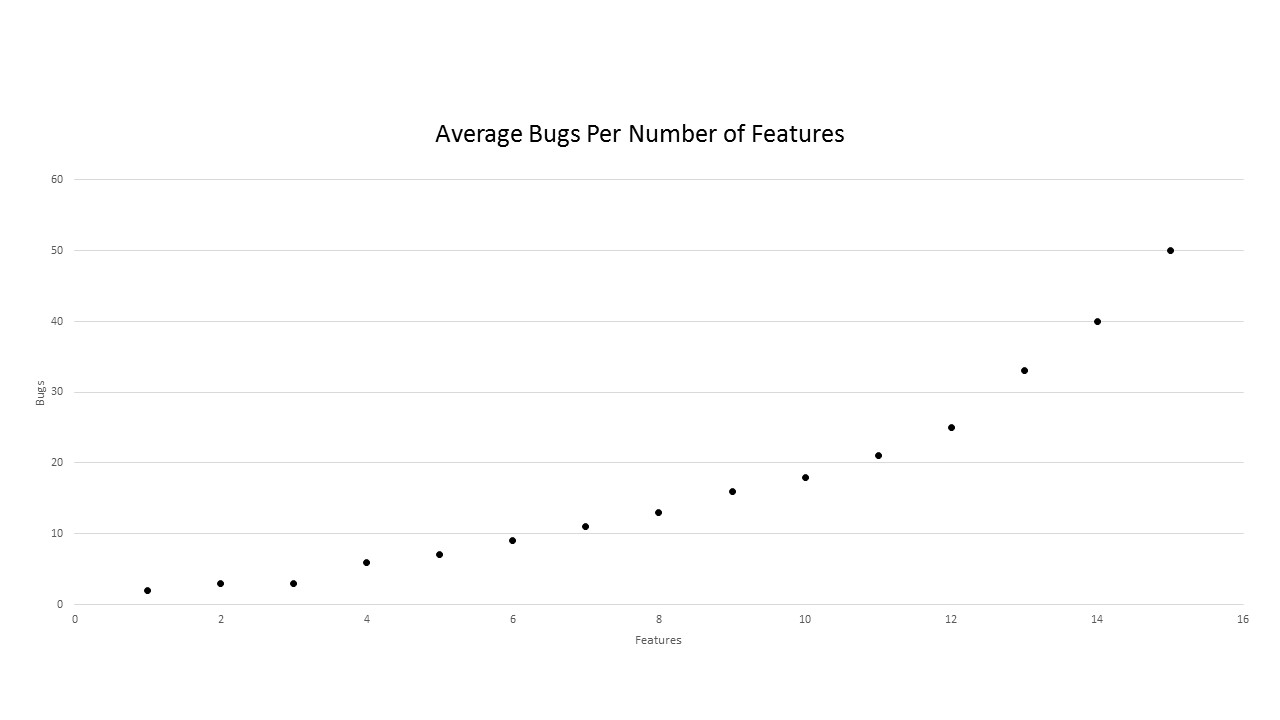
(click on image to enlarge)
As you could imagine, as the number of features introduced increases, the number of bugs introduced also increases. So, for 2 features introduced, approximately 4 bugs are created while 50 bugs are created when 15 features are added. We know that in a real-world scenario, the numbers on, at least, the Y axis - if not both axes - are substantially higher. But, this still gives us a good example. Now, you may not be too impressed with the above graph - it may not tell you all that much. But, wait…you may be missing the hidden message. In order for you to see this message, however, you’re going to have to go back to your good ole’ days of Algebra. (I know, you probably never thought you’d use any of that information again.) Specifically, you’ll need to use the standard linear equation or, more specifically, slope-intercept form:
y = mx + b
Based on the data in our scatter diagram, we can create a trend line of the values’ medians, or average. Now, look below at the a modified version of the scatter diagram from above, but now with a trend line and it’s resulting linear equation. 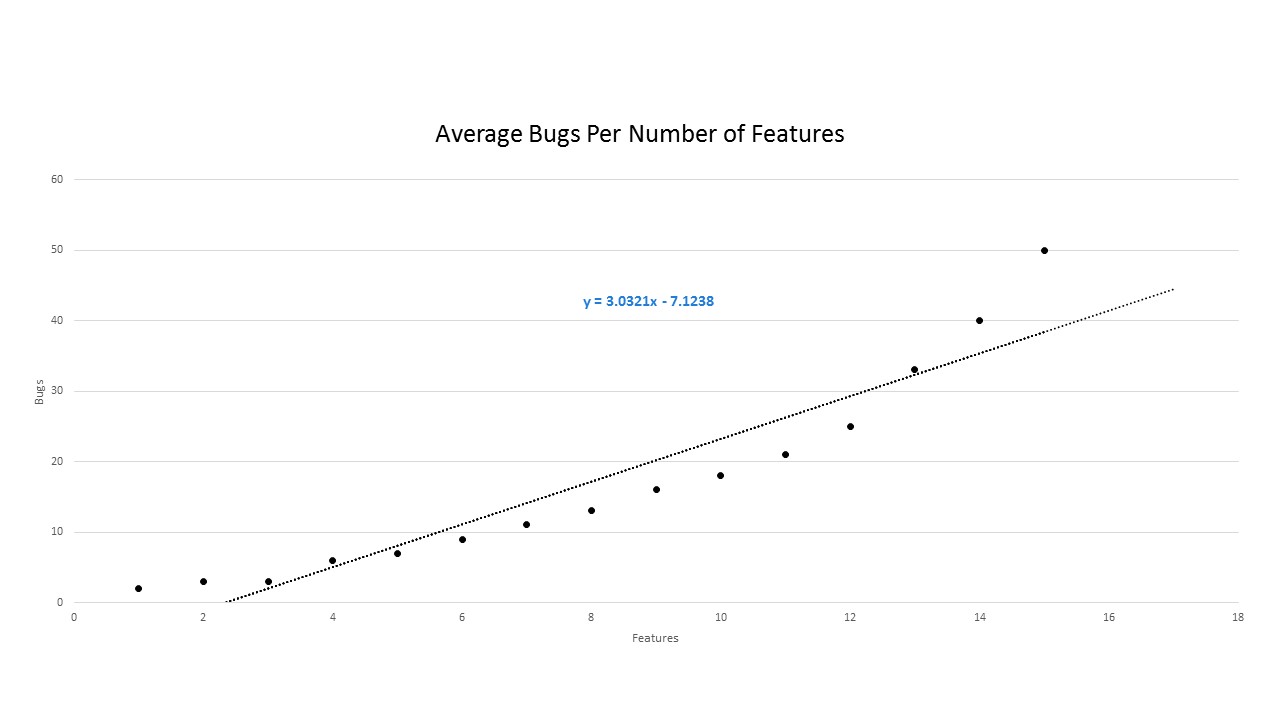
(click on image to enlarge)
Here’s the real beauty of the scatter diagram when it comes to quality assurance. Based on the trend line above, the resulting linear equation is y = 3.0321x - 7.1238. This means that, based on previous empirical data, for every x new features that are introduced to the application, we will create y bugs in the application. In other words, we can now predict approximately how many bugs will be created in the application based on how many features we choose to add to the application. Now, our quality assurance is proactive vs. reactive. So, how do we know the right amount of features that we should attempt to add to the application in a given iteration? What’s our “sweet spot?” In order to answer that question, we’ll need create another scatter diagram based on features (X) vs. number of resolved bugs per iteration (Y). This scatter diagram basically measures the velocity of your development team in resolving bugs while implementing new features. Typically, you would see this line descending, as the more time your development team implements features, the less time they spend working on fixing bugs. Once you acquire the resulting linear equation, take the equations from both of the scatter diagrams and plot them. Or, if you remember your algebra, both equations equal y. So, set both equations equal to each other and solve for x. At the point that these two lines cross, is your point of unity. In other words, this is the number of features that your team can introduce while adequately eliminating the current bugs in the system.
Sample Reports
- Ishikawa (“fishbone”) Diagram
- Check Sheet
- Stratification (alternatively, flowchart or run chart)
- Control Chart
- Histogram
- Pareto Chart
- Scatter Diagram